
This one time - we were harvesting a production bioreactor with several million dollars worth of product - an operator left a valve open and 33% of product went to drain. The plant manager (VP) was fuming mad - rightfully so.
"I pay for all this monitoring software, how come no one could tell that a valve was open?"
It's a good question. I drifted off thinking that we didn't have a tag for every valve indicating whether or not it was open.
"We need a mass balance," he said to no one in particular.
And then I realized we could have a mass-balance since we have load cells on the bioreactor and harvest tank, as well as a flow totalizer on the centrifuge. In the case of biologics processing, we are dealing with constant density volumes, which means that a mass-balance is often the same as a volume balance. The pipes between the bioreactor and the centrifuge holds volume (called "hold-up"), as well, there is hold-up between the centrifuge and the harvest tank.
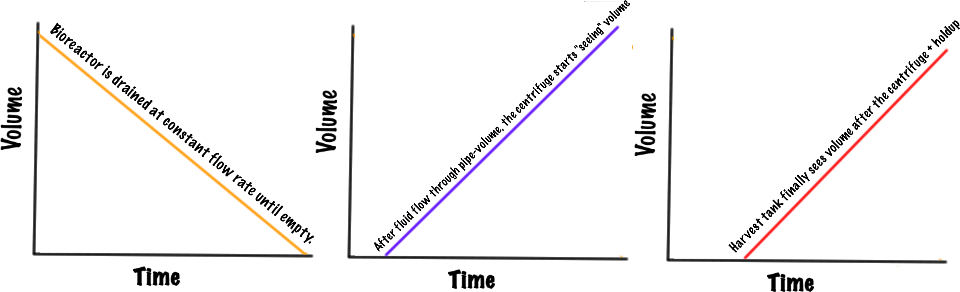
Plotted on the same trend using PI ProcessBook we get something like this:

From this perspective, we can easily determine if there is volume-loss between the centrifuge and the harvest unit by looking at the slopes: if the slopes are the same and the lines are parallel, we have no mass-loss. But it's hard to tell if there is any loss of mass between the bioreactor and the centrifuge since the line is downward sloping.
There's a trick in PI ProcessBook where you can simply reverse the Max and Min for the trace making the bottom axis the larger number and the top axis the smaller number:

This simply makes the top of the trend the small number and the bottom of the trend the larger number. Be sure to use Multiple Scales so only this tag is plotted upside-down. What you get is a trend where everything is sloping upwards:

This trend shows that the mass is balanced (i.e. no losses in the closed system).
But suppose there is a valve open on the line between the fermentor and the centrifuge... what does that look like?

In this case, we see that the slope of the totalized volume processed by the centrifuge is less than the slope of the fermentor. Literally, the rate of volume lost by the fermentor is greater than the rate of volume gained by the centrifuge... the difference is the amount gone down to drain.
Likewise, should there be losses just between the centrifuge and the harvest unit, the totalized volume of the centrifuge and fermentor volumes should match in slope, while the harvest unit should have a lesser slope.

PI ProcessBook is ideal for monitoring your process... especially if you need to know something in real-time (e.g. "Hey, there's a valve open and it shouldn't be").
In biologics manufacturing, there really is no excuse for having losses like these when we can monitor the entire system and prevent significant (in this case, seven-figure) losses in our operations.
Get Proven Biopharma PI Displays
 Zymergi serves companies that run cell culture and fermentation processes. Nearly all our customers produce biologics... molecules that are synthesized by biological organisms - and all of them get their GMP plants inspected by the FDA.
Zymergi serves companies that run cell culture and fermentation processes. Nearly all our customers produce biologics... molecules that are synthesized by biological organisms - and all of them get their GMP plants inspected by the FDA. Harvesting at day 8 means:
Harvesting at day 8 means:









 That primer came in the form of the
That primer came in the form of the 


 In essence, the UnitBatch table describes everything there is to know about a process step that happens on a unit. Remember: units are defined in the
In essence, the UnitBatch table describes everything there is to know about a process step that happens on a unit. Remember: units are defined in the 
![1fc1cbd2a59a0da04cb5e11abc816b77[1]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_t16_pRXt5UkrpnQNq99TTTuQB6QhsFCp9OXI9YZM6phtK47oeC0gugsfmt6QVjUv3_EBvkqfH2VbpGgDL57zlgbjvASn9AxyiINxBxxF1XpeWLS0LIPtM2cnWuJan3nQAJ92klhAW6PdE=s0-d)


